
2장 1절 | Y축만 깎았을 뿐인데 매출이 폭등했다
그래프는 우리에게 말없이 많은 걸 말해준다.
숫자 하나하나를 따로 읽지 않아도, 선 하나가 올라가면 “오, 성장했구나”,
막대가 크게 솟아 있으면 “이 제품이 압도적이네”라고 믿는다.
직관적이고, 빠르고, 한눈에 들어오니까.
그런데 너무 ‘빠르다’는 건,
그만큼 속기도 쉽다는 뜻이다.
그래프는 숫자보다 더 ‘설득력 있는 거짓말’을 할 수 있다
[예]
어떤 기업이 투자 유치를 앞두고 IR 자료를 만든다.
매출을 보여주는 그래프를 이렇게 꾸민다:
- 2021년: 1.1억
- 2022년: 1.2억
- 2023년: 1.35억
성장 폭은 숫자만 보면 아주 크진 않다.
하지만 Y축의 시작점을 1.0억으로 설정하고, 눈금을 0.05억 간격으로 자르면?
그래프는 이렇게 보인다:

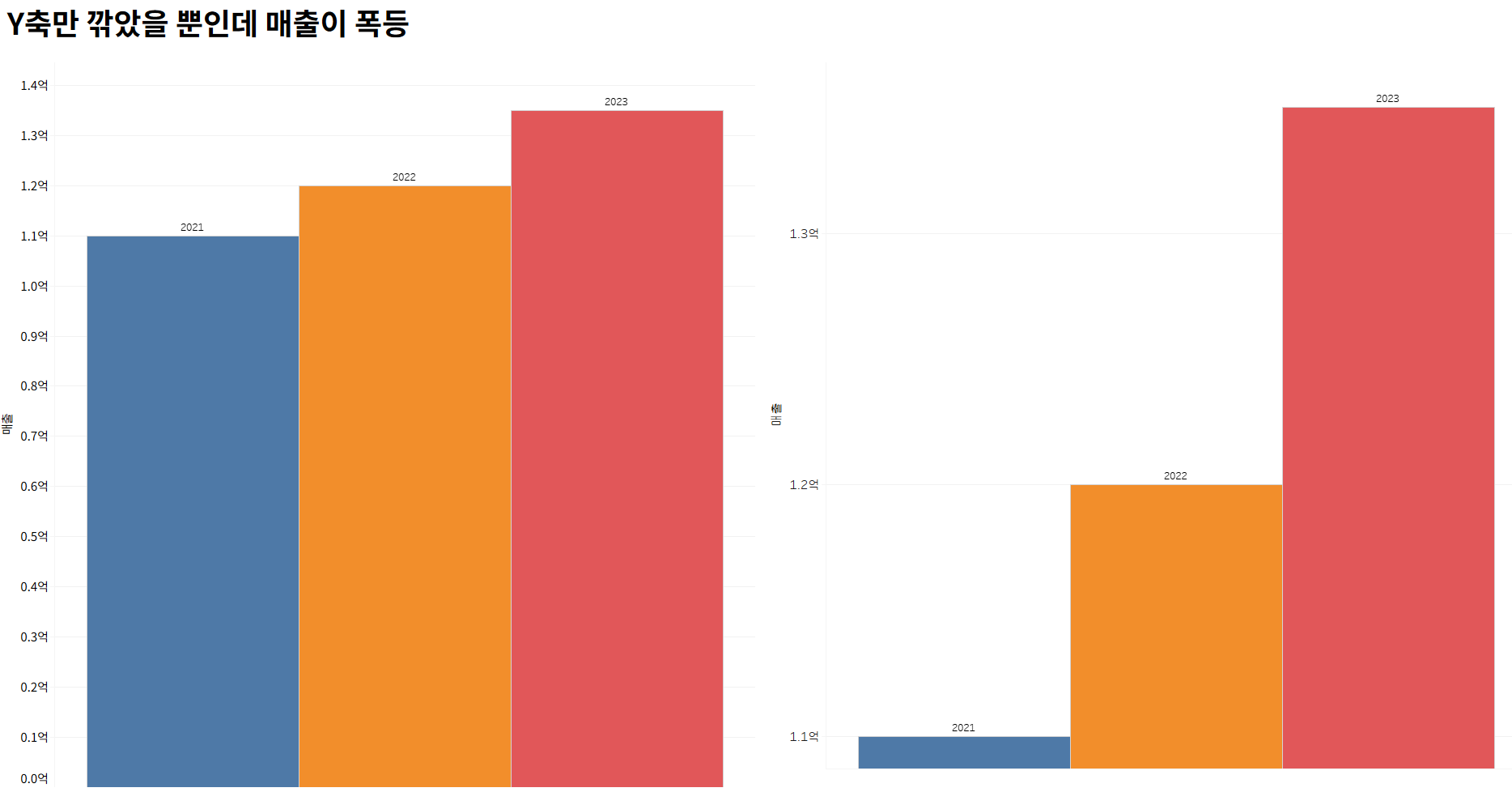
📈 1.1 → 1.2 → 1.35로 선이 급상승
막대 그래프도 마지막 해에는 마치 두 배는 뛴 것처럼 보인다.
심지어 붉은색이나 초록색을 쓰면 상승 느낌은 더욱 커진다.
같은 데이터인데, Y축 하나로 느낌이 완전히 바뀐 것이다.
이게 바로 시각화의 함정, 특히 ‘Y축 자르기(Truncated Axis)’라는 고전적 기술이다.
왜곡이라기보단 ‘편집’이다 — 그래서 더 위험하다
이 그래프는 틀리지 않았다.
숫자는 그대로고, 그래프 안의 수치도 정확하다.
그런데 문제는 “보는 사람은 그걸 그렇게 받아들이지 않는다”는 데 있다.
- 우리는 선의 기울기를 ‘속도’처럼 받아들인다.
- 막대의 길이를 ‘차이의 크기’처럼 인식한다.
- 색상, 강조, 레이블 위치 하나에도 감정이 따라간다.
즉, 그래프는 “사실을 보여주는 도구”가 아니라, “해석을 유도하는 도구”다.
그리고 이걸 아는 사람은 아주 교묘하게 ‘사실을 왜곡하지 않고 분위기를 바꾸는 연출’을 한다.
뉴스에서도 흔하게 쓰이는 기법
코로나19 백신 접종률 관련 뉴스에서 이런 사례가 있었다.
- 1차 접종률: 87%
- 2차 접종률: 83%
- 부스터 접종률: 81%
사실 큰 변화는 아니다.
그런데 방송국은 Y축을 80%부터 시작해 90%까지만 보여주는 그래프를 썼다.
결과?
- 선이 가파르게 꺾여 있다.
- 자막에는 “접종률 급감!”
- 사람들은 ‘불안’을 느낀다.
단 6%포인트의 차이를, 시각적으로는 ‘절반 가까이 줄어든 것처럼’ 보여준 셈이다.
마케팅에서 가장 자주 쓰이는 장면: 전년 대비 성장 그래프
제품 홍보 자료에서 자주 보게 되는 그래프:
- 2022년 매출: 6.1억
- 2023년 매출: 7.4억
성장률: 약 21.3% → 나쁘지 않지만, 놀랄 정도는 아님.
그런데?

- Y축 시작점을 6.0억으로, 눈금을 0.2억 간격으로 설정
- 막대 그래프 길이가 거의 두 배 차이 나 보이게 편집
- 제목: “폭발적 성장!”
- 옆에 “+1.3억 증가”라는 강조 문구까지
사실은 적당한 성장인데, 시각적으로는 폭발해 보인다.
이런 걸 보면 사람들은 "이 브랜드 잘 나가네", "투자해도 되겠다"라고 착각한다.
그것도 단 몇 초 안에.
우리는 이런 그래프를 어떻게 구별해야 할까?
1. Y축의 시작점을 확인하라
- 최소값이 0이 아닌 경우엔 과장된 그래프일 수 있음
- 특히 숫자 변화가 작을수록 ‘깎은 Y축’은 오해를 유도할 가능성 ↑
2. 눈금 간격이 일정한지 확인하라
- 0~10 구간은 1 단위인데
- 10~20 구간은 5 단위? → 왜곡된 눈금
- 이런 그래프는 의도적 조작일 가능성도 있어
3. 실제 숫자도 함께 보라
- 그래프만 보지 말고, 수치 자체를 확인하자
- 그래프는 느낌, 수치는 해석
- 둘 다 확인해야 정확한 판단 가능
4. 강조 색상이나 크기에도 주의하라
- 빨간색으로 길게 뻗은 막대? → 위기처럼 보이게 하려는 장치
- 마지막 데이터만 3D 처리된 그래프? → 시선을 그쪽으로 몰아가려는 의도
디자인이 정보보다 앞설 때, 우리는 속기 시작한다
그래프는 점점 더 감각적으로 진화하고 있다.
- 3D, 애니메이션, 인터랙티브 차트
- 인포그래픽, 아이콘 그래프, 픽토그램 등
이건 나쁘지 않다. 예쁘고 보기 좋고, 접근성이 높다.
문제는 그 디자인이 ‘정보보다 앞서버릴 때’ 생긴다.
그 순간 우리는 진실보다 분위기에 끌려가고, 숫자보다 ‘느낌’으로 판단하게 된다.
그래프는 숫자를 보여주는 도구가 아니다.
‘어떻게 보이게 할 것인가’를 디자인하는 언어다.데이터를 보는 사람이라면, 이 언어를 읽을 줄 알아야 한다.
[목차] Part1. 데이터는 왜 우리를 속이는가
[1장. “이 숫자, 진짜일까?”]
- 1-1. 매출이 200% 늘었다는데, 진짜 대박일까? ( Data literacy - 기저 효과 )
- 1-2. 평균의 함정: 내 월급은 왜 항상 평균보다 낮을까? ( Data literacy - 평균의 함정 )
- 1-3. 97%의 만족? 그 3%가 될 수 있는 나 ( Data literacy - 자기 선택 편향 )
- 1-4. 표본, 샘플, 응답률 — 누구 말을 믿을까? ( Data literacy - 비응답 편향 )
[2장. “그래프는 거짓말을 하지 않는다?”]
- 2-1. Y축만 깎았을 뿐인데 매출이 폭등했다 ( Data literacy - Y축 자르기 )
- 2-2. 누적 그래프와 막대 그래프 사이의 간극 ( Data literacy - 누적과 막대 그래프 )
- 2-3. 이중축 그래프, 도대체 뭘 비교하자는 거지? ( Data literacy - 상관관계와 인과관계 착각의 함정 )
- 2-4. 그래프는 ‘보여주는’ 게 아니라 ‘숨기는’ 도구일 때가 많다 ( Data literacy - 선택된 수치의 힘
[3장. “그래프는 거짓말을 하지 않는다?”]
- 3-1. 선택된 수치의 힘 ( Data literacy - 팩트가 많으면 진실에 가까운가? )
- 3-2. 데이터를 만든 사람의 입장 ( Data literacy - 데이터를 만든 사람의 입장 )
- 3-3. 중립을 가장한 편향 ( Data literacy - 중립을 가장한 편향 )
- 3-4. 팩트가 많으면 진실에 가까운가? ( Data literacy - 팩트가 많을수록 진실에 가까워질까? )
[4장. “당신이 클릭하는 순간, 데이터는 당신을 읽는다”]
- 4-1. 추천 알고리즘은 왜 내 취향을 이렇게 잘 알까? ( Data literacy - 추천 알고리즘은 왜 내 취향을 이렇게 잘 알까? )
- 4-2. 내가 뭘 본 줄 아는 ‘그들’의 시선 ( Data literacy - 내가 뭘 본 줄 아는 ‘그들’의 시선 )
- 4-3. 퍼스널라이징의 함정: 더는 우연이 없는 세상 ( Data literacy - 퍼스널라이징의 함정 )
- 4-4. 내가 만든 데이터가 나를 규정하는 순간 ( Data literacy - 내가 만든 데이터가 나를 규정하는 순간 )
'Data, AI, Tech. & Career' 카테고리의 다른 글
| Data literacy - 숫자에 가려진 맥락 (0) | 2025.04.10 |
|---|---|
| Data literacy - 선택된 수치의 힘 (1) | 2025.04.09 |
| Data literacy - 상관관계와 인과관계 착각의 함정 (0) | 2025.04.09 |
| Data literacy - 누적과 막대 그래프 (0) | 2025.04.08 |
| Data literacy - 비응답 편향 (0) | 2025.04.05 |
| Data literacy - 자기 선택 편향 (1) | 2025.04.05 |
| Data literacy - 평균의 함정 (0) | 2025.04.05 |
| Data literacy - 기저 효과 (1) | 2025.04.05 |



